
©2026 MKLab.
Some Rights Reserved.
Built with Hugo & hyde-hyde.
Logo made by Freepik from www.flaticon.com
©2026 MKLab.
Some Rights Reserved.
Built with Hugo & hyde-hyde.
Logo made by Freepik from www.flaticon.com


Development of scalable methods for performing content-based image search in massive image collections. Research involves a) the extension of state-of-the-art feature extraction, aggregation and indexing schemes for speeding up near-duplicate search, while maintaining competitive levels of retrieval accuracy, and b) the application and extension of dimensionality reduction and approximate computation techniques to the problem of concept detection, in both massive scale and incremental settings.
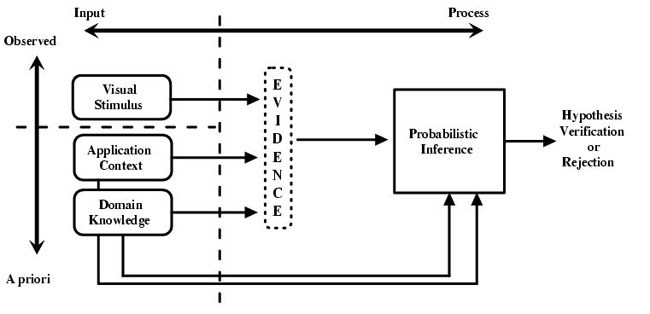
We study semantic multimedia analysis not merely as a problem of machine learning but more from the perspective of how to optimally utilize explicit knowledge and contextual information to boost the analysis efficiency. In our research we investigate different types of context ranging from the experts’ provided knowledge encoded in a formal ontology and the crowdsourced knowledge derived from the collective intelligence of social networks, all the way to knowledge that extends across media in multi-modal problems.
Development of knowledge structures, languages and tools for multimedia analysis through extension of Semantic Web languages with multimedia descriptions rules and relations. Development of reasoning techniques for multimedia applications in order to improve multimedia analysis, removal of uncertainty and integration of different analysis results, rules and relations based on spatiotemporal constraints. Development of reasoning-based ontology and content alignment techniques.
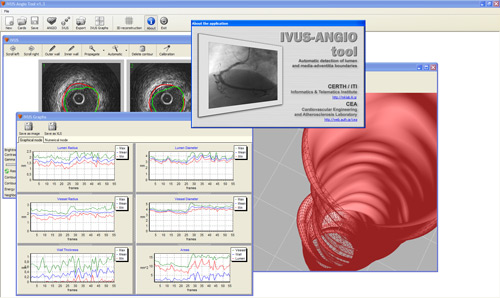
Semantic web technologies for medical applications, knowledge structures for biomedical data, intelligence processing and reasoning for diagnosis assistance and risk assessment, semantic processing of multimedia medical databases, feature extraction from medical images, medical images processing and analysis, medical tools and interfaces.
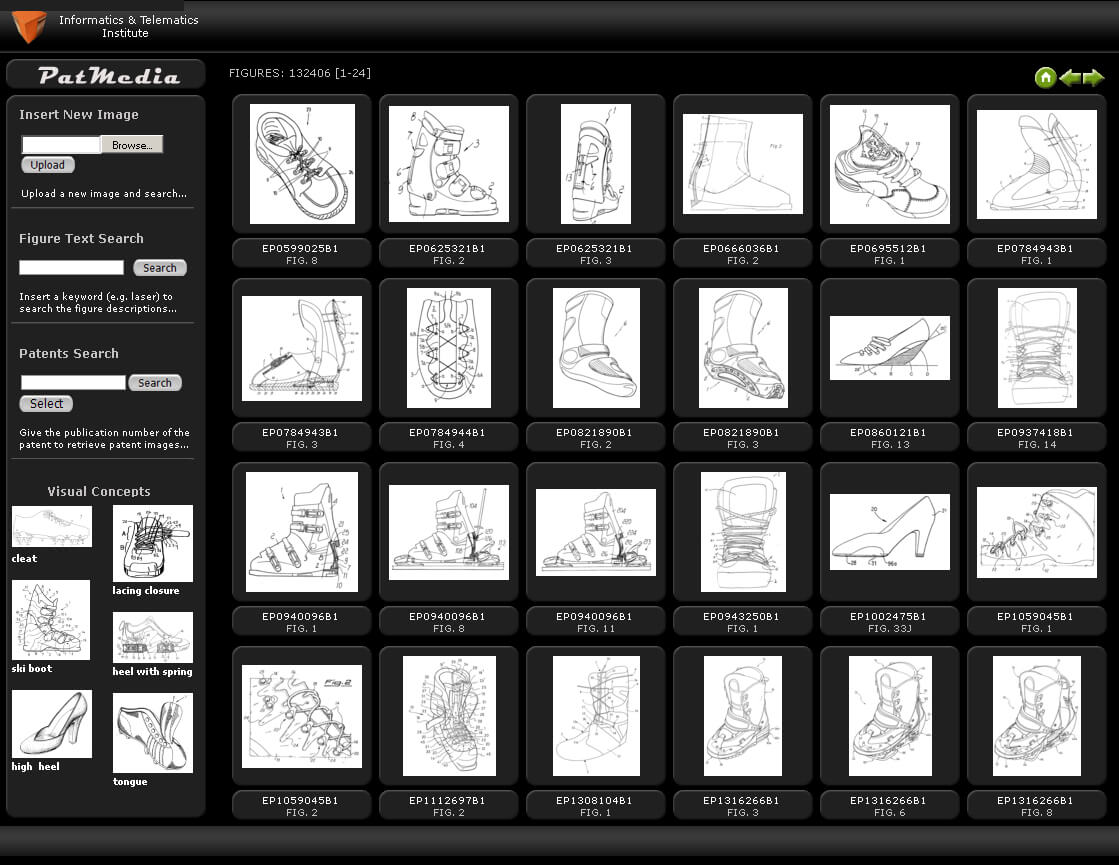
We deal with the problem of patent segmentation to images using low level visual features and machine learning techniques. We propose novel visual features in order to support content-based search of patent images and complex technical drawings. In addition, we investigate concept extraction from patent figures combining features from different modalities with early and late fusion techniques.
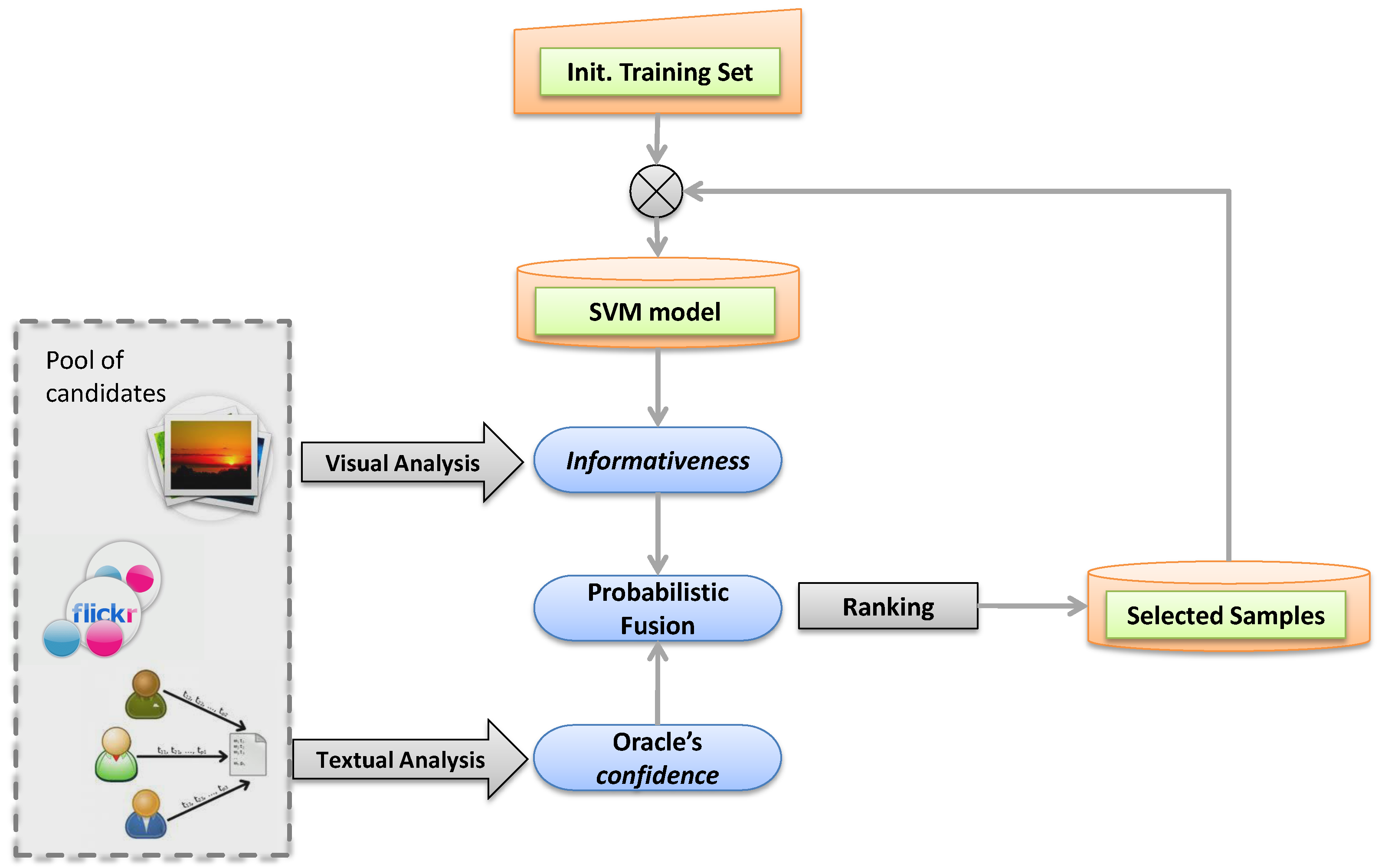
We investigate ways to fully automate the process of learning image classification models, so as to allow computer vision systems to scale in multiple domains and concepts. In particular, we study how the process of active learning can be fully automated in the context of social networks by replacing the human oracle with the user tagged images obtained from social media. New samples obtained from social media are used to expand the training set of image classifiers in both volume and variability. In addressing the noisy nature of user-contributed tags we seek to jointly maximize the informativeness of the selected samples together with our confidence about their actual content. In this way, we manage to benefit from the huge volume of multimedia content shared through social media in training computer vision systems.
We work on methods for detecting and localizing forgeries in digital media items. Research focuses on tampering localization algorithms for digital images collected from Web and social media environments. In parallel to improving the state-of-the-art in terms of detection rates, we also work on maximizing the interpretability and unambiguousness of the outputs, which usually take the form of localization heat maps.
S. Nikolopoulos, G. Th. Papadopoulos, I. Kompatsiaris and I. Patras, “Evidence driven image interpretation by combining implicit and explicit knowledge in a bayesian network”, IEEE Transactions on Systems, Man and Cybernetics – Part B: Cybernetics, vol.41, no.5, pp.1366-1381, Oct. 2011. DOI: 10.1109/TSMCB.2011.2147781 .
E. Chatzilari, S. Nikolopoulos, I. Patras, I. Kompatsiaris, “Leveraging social media for scalable object detection”, Pattern Recognition, Volume 45, Issue 8, August 2012, Pages 2962-2979, DOI: 10.1016/j.patcog.2012.02.006.
S. Nikolopoulos, S. Zafeiriou, I. Patras and I. Kompatsiaris, “High-order pLSA for indexing tagged images”, Signal Processing Elsevier, Special Issue on Indexing of Large-Scale Multimedia Signals, Volume 93, Issue 8, August 2013, Pages 2212-2228, author’s accepted manuscript
Elisavet Chatzilari, Spiros Nikolopoulos, Yiannis Kompatsiaris, Josef Kittler, “SALIC: Social Active Learning for Image Classification”, in IEEE Transactions on Multimedia, vol. 18, no. 8, pp. 1488-1503, Aug. 2016. doi: 10.1109/TMM.2016.2565440 [url] [code]
S. Vrochidis, I. Patras and I. Kompatsiaris, “Gaze Movement-driven Random Forests for Query Clustering in Automatic Video Annotation”, Multimedia Tools and Applications, 2016.
A. Moumtzidou, S. Vrochidis, E. Chatzilari and I. Kompatsiaris. “Discovery of Environmental Resources based on Heatmap Recognition”, Proceedings of the IEEE International Conference on Image Processing (ICIP 2013), Melbourne, Australia, September 15-18, 2013.
P. Sidiropoulos, S. Vrochidis, I. Kompatsiaris, “Content-Based Binary Image Retrieval using the Adaptive Hierarchical Density Histogram”, Pattern Recognition Journal, Elsevier, Volume 44, Issue 4, pp 739-750, April 2011.
E. Spyromitros-Xioufis, S. Papadopoulos, Y. Kompatsiaris, G. Tsoumakas, I. Vlahavas, “A Comprehensive Study over VLAD and Product Quantization in Large-scale Image Retrieval”, IEEE Transactions on Multimedia 16(6), pp. 1713-1728, October 2014.
E. Mantziou, S. Papadopoulos, Y. Kompatsiaris, “Learning to detect concepts with Approximate Laplacian Eigenmaps in large-scale and online settings”, International Journal of Multimedia Information Retrieval 4(2), pp. 95-111, 2015
S. Vrochidis, A. Moumtzidou, and I. Kompatsiaris, “Concept-based Patent Image Retrieval”, World Patent Information Journal, Volume 34, Issue 4, pp. 292-303, December 2012.